2. 2025-09-15
2.1. Konzepte
2.1.2. Internet für Maschinen und Prozesse (verteilte Systeme)
-
(SOAP)
-
REST
-
graphQL
-
gRPC
-
WebSockets
-
SSE
-
MQTT
2.1.3. REST
-
REpresentational State Transfer
-
HTTP Methoden
-
Übertragung beliebiger Text- (HTML, XML, JSON, …) und Binärformate (Images, PDF, …)
-
jedoch relativ starr
-
gut geeignet für CRUD Operationen (Create, Read, Update, Delete)
-
mehrere Endpoint URLs
-
Overhead durch HTTP Header
| proprietär … firmenspezifisch (nicht offengelegt, nicht standardisiert, nicht interoperabel) |
2.1.4. graphQL
-
von Facebook entwickelt
-
Abfragesprache für APIs
-
flexible Abfragen
-
nur eine einzige Endpoint URL
-
gut geeignet für komplexe Datenstrukturen
-
weniger Overhead als REST
-
stark typisiert
2.1.5. gRPC
-
von Google entwickelt
-
Remote Procedure Call (RPC) Framework
-
basiert auf HTTP/2
-
unterstützt mehrere Programmiersprachen
-
effizient und schnell
-
stark typisiert
-
unterstützt Streaming
-
benötigt Protokollpuffer (Protocol Buffers) zur Definition der Schnittstellen
-
gut geeignet für Microservices
2.1.7. SSE (Server-Sent Events)
-
unidirektionale Kommunikation (Server zu Client)
-
Echtzeit-Updates
-
textbasierte Daten (meist JSON)
-
einfach zu implementieren
-
gut geeignet für Benachrichtigungen, Newsfeeds
2.1.8. MQTT (Message Queuing Telemetry Transport)
-
leichtgewichtiges Publish-Subscribe-Protokoll
-
für IoT (Internet of Things) entwickelt
-
funktioniert über TCP/IP
-
geringerer Overhead
-
gut geeignet für ressourcenbeschränkte Geräte
-
unterstützt QoS (Quality of Service) Level
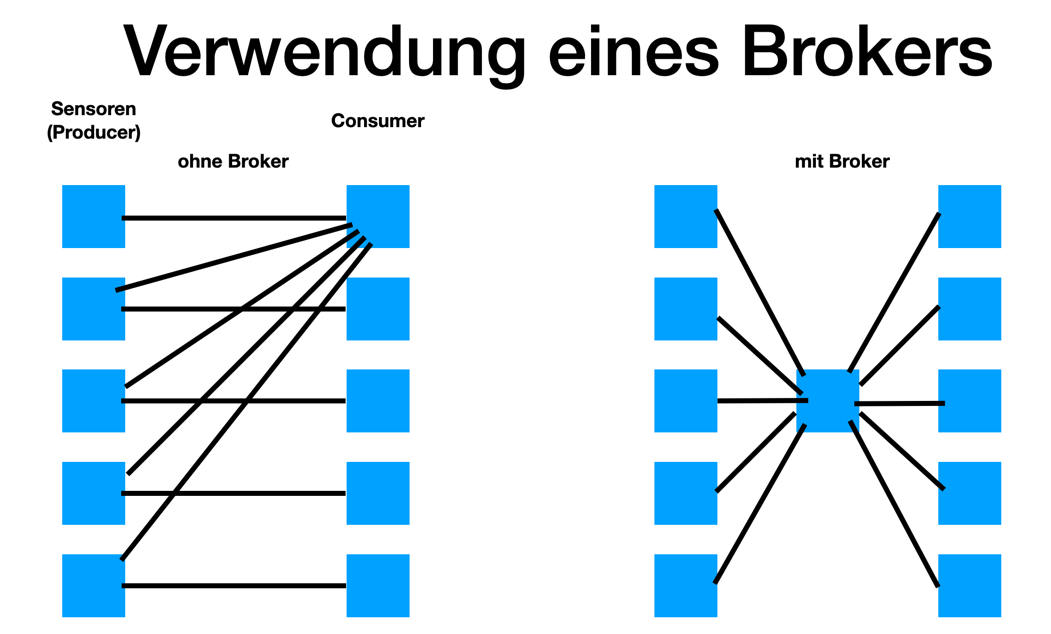
2.1.9. Publish-Subscribe vs Observer Pattern (vom copilot)
Der Hauptunterschied zwischen Publish-Subscribe und Observer Pattern liegt in der Entkopplung und dem Kommunikationsmodell:
-
Observer Pattern:
-
Direkte Kopplung zwischen Subjekt (Subject) und Beobachtern (Observers).
-
Das Subjekt kennt alle seine Beobachter und benachrichtigt sie direkt bei Änderungen.
-
Wird meist innerhalb einer Anwendung verwendet (z.B. GUI-Events).
-
-
Publish-Subscribe:
-
Lose Kopplung durch einen Vermittler (Message Broker).
-
Publisher und Subscriber kennen sich nicht direkt.
-
Nachrichten werden an einen Kanal/Topic gesendet und von allen interessierten Subscribern empfangen.
-
Häufig in verteilten Systemen eingesetzt (z.B. MQTT, EventBus).
-
Zusammengefasst: Observer ist direkt und synchron, Publish-Subscribe ist indirekt, asynchron und skalierbarer.
3. 2025-10-06
JAX-RS (Jakarta RESTful Web Services) * ist eine Spzifikation (Standard) für die Entwicklung von RESTful Web Services in Java
-
Teil von Jakarta EE (früher Java EE)
3.1. Response Typen bei JAX-RS
-
bei REST-Endpoints können verschiedene Response-Typen zurückgegeben werden, abhängig von der Anforderung und dem Kontext
-
die häufigsten Rückgabetypen der REST-Endpoint-Methoden sind:
-
String
-
Entity zB Person
-
Response: enthält Statuscode, Header und Entity und mehr zB Cookies
-
…
-
5. 2025-10-06
5.1. Prüfungsfragen – Zusammenfassung
5.1.1. Was ist proprietär?
Proprietär bedeutet firmenspezifisch oder nicht standardisiert. Eine proprietäre Software oder Technologie gehört einem bestimmten Unternehmen, das die Kontrolle über deren Nutzung, Änderung und Weitergabe behält. Beispiel: Microsoft Word ist proprietär, während LibreOffice Open Source ist.
5.1.2. Was ist ein Handshake?
Ein Handshake ist ein Kommunikationsprozess zwischen zwei Systemen (z. B. Client und Server oder Browser und Server), bei dem sie sich gegenseitig über Verbindungsparameter, Verschlüsselung oder Authentifizierung einigen. Beispiel: Beim Aufbau einer HTTPS-Verbindung erfolgt ein TLS-Handshake.
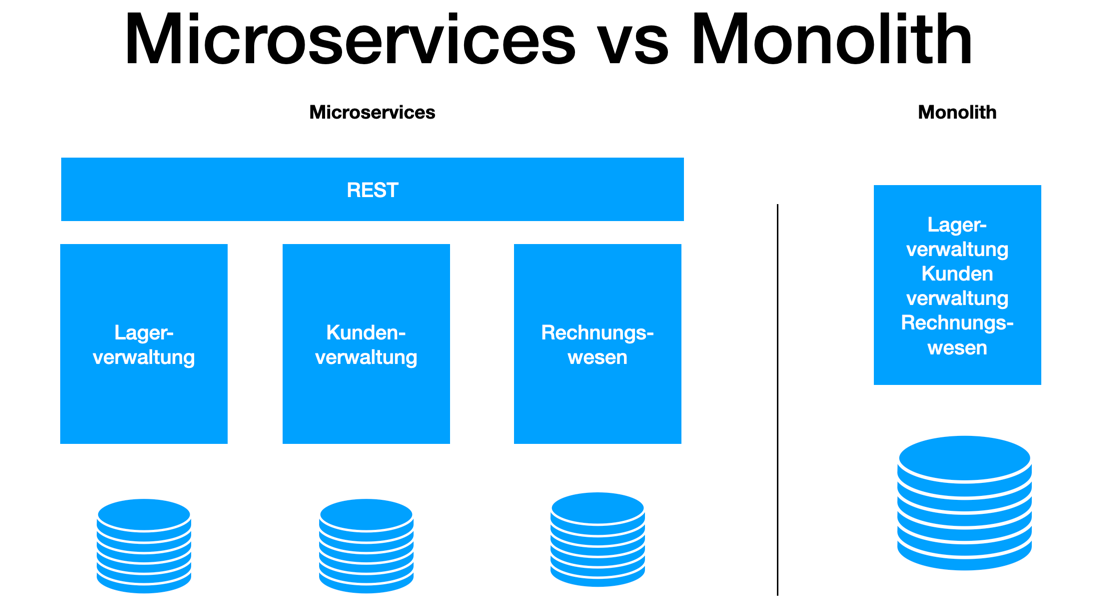
5.1.3. Unterschied Microservice vs. Monolith
-
Monolith: Eine Anwendung besteht aus einem großen Block mit allen Funktionen und Modulen gemeinsam. Änderungen sind oft schwierig und erfordern ein erneutes Deployment der gesamten Anwendung.
-
Microservices: Die Anwendung ist in mehrere kleine, unabhängige Services aufgeteilt. Jeder Service kann separat entwickelt, getestet, deployed und skaliert werden.
5.1.4. GraphQL vs. REST
-
REST:
-
Nutzt mehrere Endpunkte (z. B.
/users,/products). -
Server bestimmt, welche Daten zurückgegeben werden.
-
Kann zu Overfetching oder Underfetching führen.
-
-
GraphQL:
-
Nur ein einziger Endpunkt.
-
Client bestimmt selbst, welche Daten er benötigt.
-
Spart Bandbreite und reduziert unnötige Datenübertragung.
-
5.1.5. Was ist referenzielle Integrität?
Die referenzielle Integrität stellt sicher, dass Beziehungen zwischen Tabellen in einer Datenbank konsistent bleiben. Wenn ein Fremdschlüssel in einer Tabelle auf eine andere Tabelle verweist, darf der referenzierte Datensatz nicht gelöscht oder verändert werden, ohne die Beziehung anzupassen. Beispiel: Ein Schüler-Datensatz darf nicht existieren, wenn seine Schule gelöscht wurde.
5.1.6. Master-Detail-Tabellenbeziehung
Eine Master-Detail-Beziehung (auch 1:n-Beziehung) beschreibt, dass: - eine Master-Tabelle (z. B. Kunde) mehrere Detail-Datensätze (z. B. Bestellungen) haben kann. - Die Detail-Tabelle enthält einen Fremdschlüssel zur Master-Tabelle.
5.1.7. Orphaned Record
Ein Orphaned Record (verwaister Datensatz) ist ein Datensatz, der keine Verbindung mehr zu seinem übergeordneten Datensatz hat. Das passiert z. B., wenn ein übergeordneter Datensatz gelöscht wird, aber abhängige Datensätze bestehen bleiben. Dies führt zu Dateninkonsistenz und sollte durch referenzielle Integrität verhindert werden.
5.1.8. Restrict vs. Cascading Delete vs. Nullify
-
Restrict: Das Löschen eines übergeordneten Datensatzes wird verhindert, wenn abhängige Datensätze existieren.
-
Cascading Delete: Beim Löschen eines übergeordneten Datensatzes werden alle abhängigen Datensätze automatisch mitgelöscht.
-
Nullify: Beim Löschen des übergeordneten Datensatzes wird der Fremdschlüssel in den abhängigen Datensätzen auf NULL gesetzt.
5.1.9. Was ist JACKSON?
Jackson ist eine Java-Bibliothek zum (De-)Serialisieren von JSON-Daten. Sie wandelt JSON in Java-Objekte um und umgekehrt. Dieser Prozess wird auch Marshalling (Serialisierung) und Unmarshalling (Deserialisierung) genannt.
5.1.10. Was ist JAX-RS?
JAX-RS (Java API for RESTful Web Services) ist eine Java-Spezifikation zur Erstellung von REST-APIs.
Sie verwendet Annotationen wie @GET, @POST, @Path, @Produces, um HTTP-Endpunkte einfach zu definieren.
5.1.11. Was ist ein Singleton?
Das Singleton-Pattern stellt sicher, dass von einer Klasse nur eine Instanz existiert. Diese Instanz ist global zugänglich. Typisches Beispiel: Eine zentrale Logger- oder Konfigurationsklasse.
5.1.12. Convention over Configuration
Ein Software-Prinzip, das besagt: > „Wenn du dich an die Konventionen hältst, musst du nichts konfigurieren.“
Das bedeutet, dass Frameworks Standardverhalten automatisch übernehmen, solange der Entwickler sich an gewisse Namens- oder Strukturkonventionen hält.
Beispiel: In Quarkus wird application.properties automatisch erkannt.
5.1.13. Was ist ein Paradigma?
Ein Paradigma ist ein grundlegendes Denk- oder Programmierkonzept, das vorgibt, wie Software strukturiert und entwickelt wird. Beispiele: - Objektorientiert (Java, C++) - Funktional (Haskell, JavaScript) - Prozedural ©
5.1.14. Was ist eine Objektidentität?
Die Objektidentität beschreibt die eindeutige Existenz eines Objekts im Speicher. Zwei Objekte können denselben Inhalt haben, aber verschiedene Identitäten besitzen. In Java wird die Identität durch den Speicherort (Referenz) bestimmt. Beispiel:
Person p1 = new Person("John");
Person p2 = new Person("John");p1.equals(p2) kann true sein (gleicher Inhalt), aber p1 == p2 ist false (unterschiedliche Identität).
6. 2025-10-13
6.1. CDI - Contexts and Dependency Injection
-
Man erzeugt Objekte nicht selbst mit
new, sondern lässt sie vom Framework bereitstellen (Inversion of Control - IoC) -
zB ohne CDI
PersonRepository personRepository = new PersonRepository(); -
zB mit CDI
@Inject PersonRepository personRepository; -
mit Dependency Injection (DI) werden die Referenzen auf - bereits vom übergeordneten DI-Container erzeugte - Objekte automatisch gesetzt -man spricht hier von injizieren.
-
Der Begriff Context gibt die Lebensdauer und Sichtbarkeit der Objekte an.
-
@ApplicationScoped
-
@RequestScoped
-
@SessionScoped
-
@Dependent (Standard)
-
7. 2025-11-03
Normalisierung
-
Was ist die 1.NF?
Antwort
-
Jedes Attribut enthält nur atomare Werte (unteilbar).
-
Es gibt keine wiederholten Gruppen oder Mehrfachwerte.
-
Jede Zeile ist eindeutig identifizierbar (durch Primärschlüssel).
-
Was ist die 2.NF?
Antwort
-
Erfüllt die Anforderungen der 1.NF.
-
Jedes Nicht-Schlüsselattribut ist vollständig funktional abhängig vom gesamten Primärschlüssel (nicht nur von einem Teil davon, wenn der Primärschlüssel aus mehreren Attributen besteht).
-
Was ist die 3.NF?
Antwort
-
Erfüllt die Anforderungen der 2.NF.
-
Es gibt keine transitiven Abhängigkeiten zwischen Nicht-Schlüsselattributen. (Ein Nicht-Schlüsselattribut darf nicht von einem anderen Nicht-Schlüsselattribut abhängen).
-
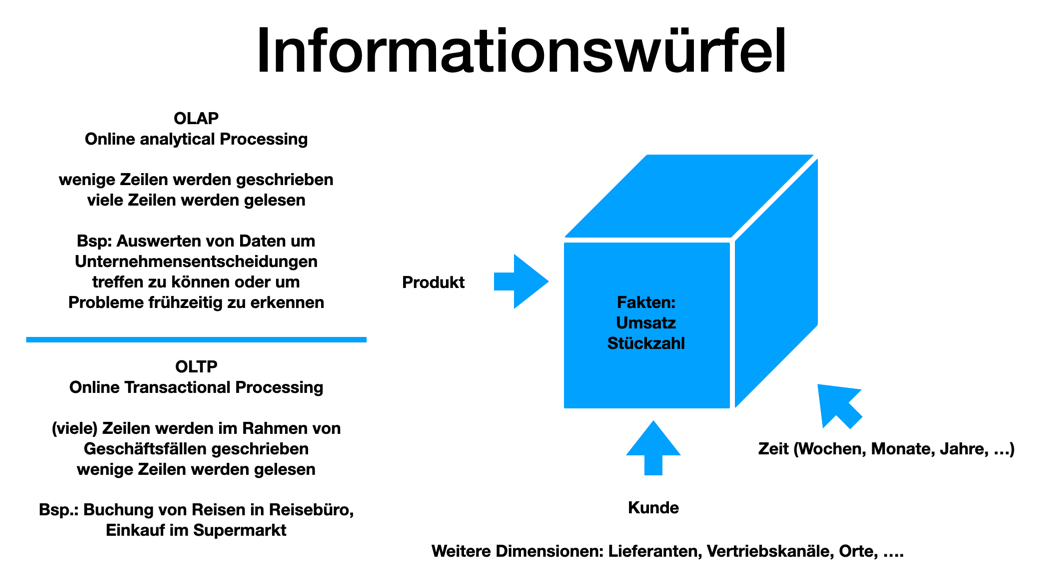
Warum tut man normalisieren?
Antwort
-
Zur Abfragen der Daten nach unterschiedlichen Dimensionen (zB Kunde nach Region, Produktkategorie, Zeiträume, …). Die Fakten (Measures) sind meist numerische Werte (zB Umsatz, Menge, …), die analysiert werden.
-
Reduziert Datenredundanz und Inkonsistenzen.
-
Verbessert Datenintegrität.
-
Erleichtert Wartung und Updates der Datenbank.
8. 2025-11-10
1. Test – Stoff
-
Datenmodell aufsetzen
-
Testfälle schreiben
-
AssertJ-DB
-
REST-Services
Was sind Entity-Klassen?
-
Java-Klassen, die mit
@Entityannotiert sind -
Werden per JPA/Hibernate einer Datenbanktabelle zugeordnet
-
Felder entsprechen Tabellenspalten
-
Besitzen mindestens einen Primärschlüssel (
@Id) -
Dienen als Abbild der tatsächlichen Geschäftsobjekte (z. B. User, Product, Cart) → Bsp: Früher wurden diese Daten in Aktenschränken / -ordnern aufbewahrt, heute in Datenbanken.

8.1. Klassendiagramm angezeigt bekommen
-
Klassen markieren → Rechtsklick → Diagrams → Java Klassen → Diagram wird angezeigt
-
Fields und show Dependencies anklicken → Beziehungen und Attribute werden angegzeigt.
-
Rechtsklick im Diagramm → Layout → Nets → organic
-
Rechtsklick im Diagramm → Appearance → Standard
-
8.2. Beziehungen
8.2.1. Fetch-Strategien — LAZY vs. EAGER
-
LAZY (Standard bei 1:n, n:m) Daten werden erst geladen, wenn darauf zugegriffen wird → bessere Performance
-
EAGER (Standard bei 1:1, n:1) Verknüpfte Daten werden sofort mitgeladen → kann mehr laden als nötig
Faustregel: → Immer LAZY, außer es gibt einen guten Grund.
8.2.2. Kardinalität / Multiplizität
Annotation |
Beziehung |
Bedeutung |
@OneToOne |
1 : 1 |
Ein Objekt → ein Objekt |
@OneToMany |
1 : n |
Ein Objekt → viele |
@ManyToOne |
n : 1 |
Viele → eins |
@ManyToMany |
n : m |
Viele ↔ viele |
8.2.3. Triple-A-Pattern (AAA)
Strukturierungskonzept für Unit-Tests → klar, einfach, gut lesbar.
-
Arrange Test vorbereiten: Objekte anlegen, Daten initialisieren, mocks konfigurieren
-
Act Aktion ausführen: die zu testende Methode aufrufen
-
Assert Ergebnis prüfen: Erwartetes Resultat mit tatsächlichem vergleichen
@Test
void testAdd() {
// Arrange
Calculator calc = new Calculator();
// Act
int result = calc.add(2, 3);
// Assert
assertEquals(5, result);
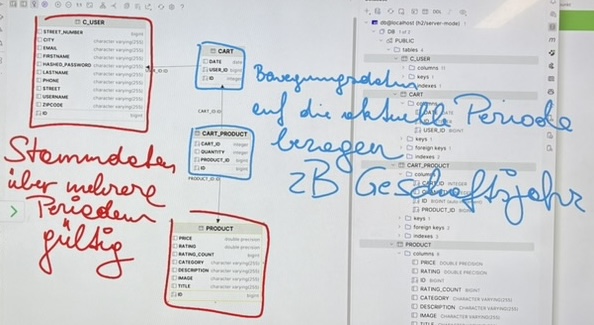
}8.2.4. Stammdaten & Bewegungsdaten
-
entstehen in Geschäftsprozessen
-
Stammdaten
-
Langfristig gültige (mehrere Geschäftsjahre), selten veränderte Grunddaten (ev. die Adresse eines Kunden oder Mitarbeiters)
-
Beschreiben Objekte/Personen unabhängig von Vorgängen
-
Beispiele: Kunden, Produkte, Mitarbeiter
-
-
Bewegungsdaten
-
sind meist einer Periode zuzuordnen, zB einem Geschäftsjahr
-
Verändern sich laufend, beziehen sich auf Stammdaten
-
werden eher nie verändert: zB wird eine Rechnung nicht mehr geändert, wenn sie einmal erstellt wurde
-
Beispiele: Bestellungen, Rechnungen, Buchungen
-
9. 2026-01-12
10. 2026-02-09
10.1. graphQL
-
Warum graphQL?
-
Flexibilität: Clients können genau die Daten anfordern, die sie benötigen, und nicht mehr.
-
Effizienz: Reduziert die Anzahl der Anfragen, da mehrere Ressourcen in einer einzigen Anfrage abgefragt werden können.
-
Starke Typisierung: Das Schema definiert die verfügbaren Daten und deren Typen,was die Entwicklung und Fehlersuche erleichtert.
-
Echtzeit-Updates: Unterstützt Subscriptions für Echtzeit-Kommunikation.
-
Gute Dokumentation: Das Schema dient als Dokumentation der API
-
11. 2026-02-23
-
graphQL-Beispiel besprochen
-
Was ist ein graphQL-Schema?
-
Ein graphQL-Schema definiert die Struktur der Daten, die von einem graphQL-Server bereitgestellt werden. Es beschreibt die verfügbaren Typen, Felder und Beziehungen zwischen den Daten.
-
Es dient als Vertrag zwischen Client und Server, der festlegt, welche Daten abgefragt werden können und wie sie strukturiert sind.
-
-
graphQL-Endpoint
package at.htl.vehicle.boundary;
import at.htl.vehicle.control.VehicleRepository;
import at.htl.vehicle.entity.Vehicle;
import org.eclipse.microprofile.graphql.*;
import jakarta.inject.Inject;
import jakarta.transaction.Transactional;
import java.util.List;
@GraphQLApi
public class VehicleGraphQlApi {
@Inject
VehicleRepository vehicleRepository;
@Query("allVehicles")
@Description("Get all vehicles from the gallery")
public List<Vehicle> getAllVehicles() {
return vehicleRepository.listAll();
}
@Query("vehicle")
@Description("Get a specific vehicle by its id")
public Vehicle getVehicle(@Name("vehicleId") Long id) {
return vehicleRepository.findById(id);
}
@Mutation("createVehicle")
@Description("Add a new vehicle to the gallery")
@Transactional
public Vehicle createVehicle(Vehicle vehicle) {
vehicleRepository.persist(vehicle);
return vehicle;
}
@Mutation("deleteVehicle")
@Description("Remove a vehicle from the gallery")
@Transactional
public boolean deleteVehicle(@Name("vehicleId") Long id) {
return vehicleRepository.deleteById(id);
}
}-
graphQL-Clients
-
Debug-page
-
intellij-client
-
cli-Tools (zB curl, httpie, httpyac, …)
-
12. 2026-03-02
12.1. Welche Parameter-typen gibt es bei http? (S. Sperrer)
12.1.1. Pathparam
https://www.beispiel.de/api/users/123Hier ist 123 ein Pathparam, der die ID des Benutzers angibt, den wir abrufen möchten.w
12.1.2. Queryparam
https://www.beispiel.de/api/users?name=Max&age=30Hier sind name=Max und age=30 Queryparameter,
die zusätzliche Informationen über die Anfrage liefern (z. B. Filterkriterien).
12.2. Aufbau eines http-requests (Anfrage)
Ein Client (zB Browser) sendet einen Request an den Server.
| Komponente | Beschreibung |
|---|---|
Startzeile |
Enthält Methode, Pfad und Version (z.B. |
Header |
Metadaten wie |
Leerzeile |
Trennt Header vom Body. |
Body |
Enthält Daten (optional, primär bei POST/PUT). |
POST /api/login HTTP/1.1
Host: www.beispiel.de
Content-Type: application/json
Content-Length: 34
{
"user": "admin",
"pass": "1234"
}12.3. Aufbau der HTTP-Response (Antwort)
Der Server antwortet auf den Request mit dem Ergebnis der Verarbeitung.
| Komponente | Beschreibung |
|---|---|
Statuszeile |
Enthält Version, Statuscode und Nachricht (z.B. |
Header |
Infos vom Server (z.B. |
Leerzeile |
Trennt Header vom Body. |
Body |
Die eigentlichen Daten (HTML, JSON, Bild). |
HTTP/1.1 200 OK
Date: Mon, 02 Mar 2026 10:30:00 GMT
Server: Apache/2.4.41
Content-Type: text/html
<html>
<body>
<h1>Willkommen!</h1>
</body>
</html>12.4. WebSockets
WebSockets wurden entwickelt, um die Einschränkungen des klassischen HTTP-Protokolls zu überwinden und echte Interaktivität im Browser zu ermöglichen.
12.4.1. Das Kernproblem: Die HTTP-Einbahnstraße
Traditionelles HTTP folgt einem strikten Request-Response-Modell.
-
Zustandslosigkeit: Jede Anfrage steht für sich allein.
-
Client-getrieben: Der Server darf nicht von sich aus sprechen. Er muss warten, bis der Browser fragt: "Gibt es etwas Neues?"
-
Overhead: Für jede kleine Nachricht (z. B. ein "Hi" im Chat) müssen HTTP-Header mitgeschickt werden, was Bandbreite und Zeit kostet.
12.4.2. Die Lösung durch WebSockets
Ein WebSocket ermöglicht eine Full-Duplex-Verbindung. Nach einem initialen Handshake bleibt die Verbindung offen.
-
Server-Push: Der Server sendet Daten sofort, wenn sie entstehen.
-
Geringe Latenz: Kein ständiger Verbindungsaufbau nötig.
-
Effizienz: Die Header-Daten sind nach dem Handshake minimal.
12.4.3. Unterschied: WebSocket vs. Socket
Obwohl die Namen ähnlich sind, arbeiten sie auf unterschiedlichen Abstraktionsebenen des Netzwerks.
| Merkmal | Klassischer Socket (TCP) | WebSocket |
|---|---|---|
OSI-Schicht |
Schicht 4 (Transport) |
Schicht 7 (Anwendung) |
Protokoll |
Pures TCP |
Basiert initial auf HTTP (Upgrade) |
Einsatzort |
Systemprogrammierung (C++, Java, Go) |
Webbrowser und Webserver |
Firewalls |
Oft blockiert (außer Standardports) |
Passiert Port 80/443 problemlos. Firewalls erkennen es als normalen HTTP-Verkehr. |
Abstraktion |
"Roh" (Byte-Streams) |
Nachrichtenbasiert (Frames) |
12.5. 1. Sockets (Network Sockets)
Ein Socket ist der fundamentale Endpunkt einer Netzwerkverbindung im Betriebssystem.
| Programmierer müssen bei Sockets oft selbst definieren, wo eine Nachricht anfängt und wo sie aufhört (Framing). |
12.5.1. WebSockets
WebSockets sind ein Protokoll, das auf Sockets aufbaut. Da Browser aus Sicherheitsgründen keinen direkten Zugriff auf rohe TCP-Sockets erlauben, fungiert der WebSocket als "sicherer Proxy" für Web-Anwendungen.
12.5.2. Typische Anwendungsfälle
-
Finanz-Apps: Live-Aktienkurse ohne Verzögerung.
-
Collaboration Tools: Wenn mehrere Personen gleichzeitig an einem Dokument arbeiten.
-
Gaming: Multiplayer-Browser-Spiele mit schnellen Reaktionszeiten.
-
Messenger: Sofortige Zustellung von Chat-Nachrichten.
| Wähle WebSockets, wenn du eine dauerhafte Verbindung für bidirektionalen Datenaustausch im Web benötigst. Nutze Sockets, wenn du außerhalb des Browsers maximale Kontrolle über den Netzwerkverkehr brauchst. |
12.6. Exkurs: GraphQL vs. REST Response-Handling in Quarkus
In Quarkus (SmallRye GraphQL) ist es ein fundamentaler Unterschied zu JAX-RS (REST), wie Antworten an den Client gesendet werden.
12.6.1. Die kurze Antwort
In GraphQL ist es absolut unüblich, ein generisches Response-Objekt (wie javax.ws.rs.core.Response) zurückzugeben.
Während du in REST Header, Statuscodes und Body manuell verpackst, übernimmt bei GraphQL das Framework die Kapselung der Daten.
12.6.2. Warum kein Response-Objekt?
1. Der HTTP-Statuscode ist (fast) immer 200
Im Gegensatz zu REST landen alle GraphQL-Anfragen per POST auf einem einzigen Endpunkt (meist /graphql).
* Selbst bei fachlichen Fehlern antwortet der Server technisch mit einem HTTP 200 OK.
* Fehlerinformationen werden im errors-Feld des JSON-Bodys transportiert, nicht über den HTTP-Header.
12.6.3. Vergleich: REST vs. GraphQL
| Feature | REST (JAX-RS) | GraphQL (SmallRye) |
|---|---|---|
Rückgabetyp |
|
Direktes Daten-Objekt (POJO/Entity) |
Statuscodes |
200, 201, 400, 404, 500 etc. |
Fast immer 200 OK |
Fehler-Handling |
|
Exceptions (werden zu |
Code-Beispiel (Quarkus GraphQL)
So implementierst du einen sauberen Endpoint ohne manuelles Response-Objekt:
@Query
public User getUser(Long id) {
User user = repository.findById(id);
if (user == null) {
// Diese Exception wird vom Framework in einen GraphQL-Error gewandelt
throw new GraphQLException("User mit ID " + id + " nicht gefunden");
}
return user; // Das Framework kümmert sich um das JSON-Gerüst
}|
Das |
13. 2026-04-13 (S. Sperrer)
13.1. Web Sockets
Neu: Web Sockets Next (in Quarkus)
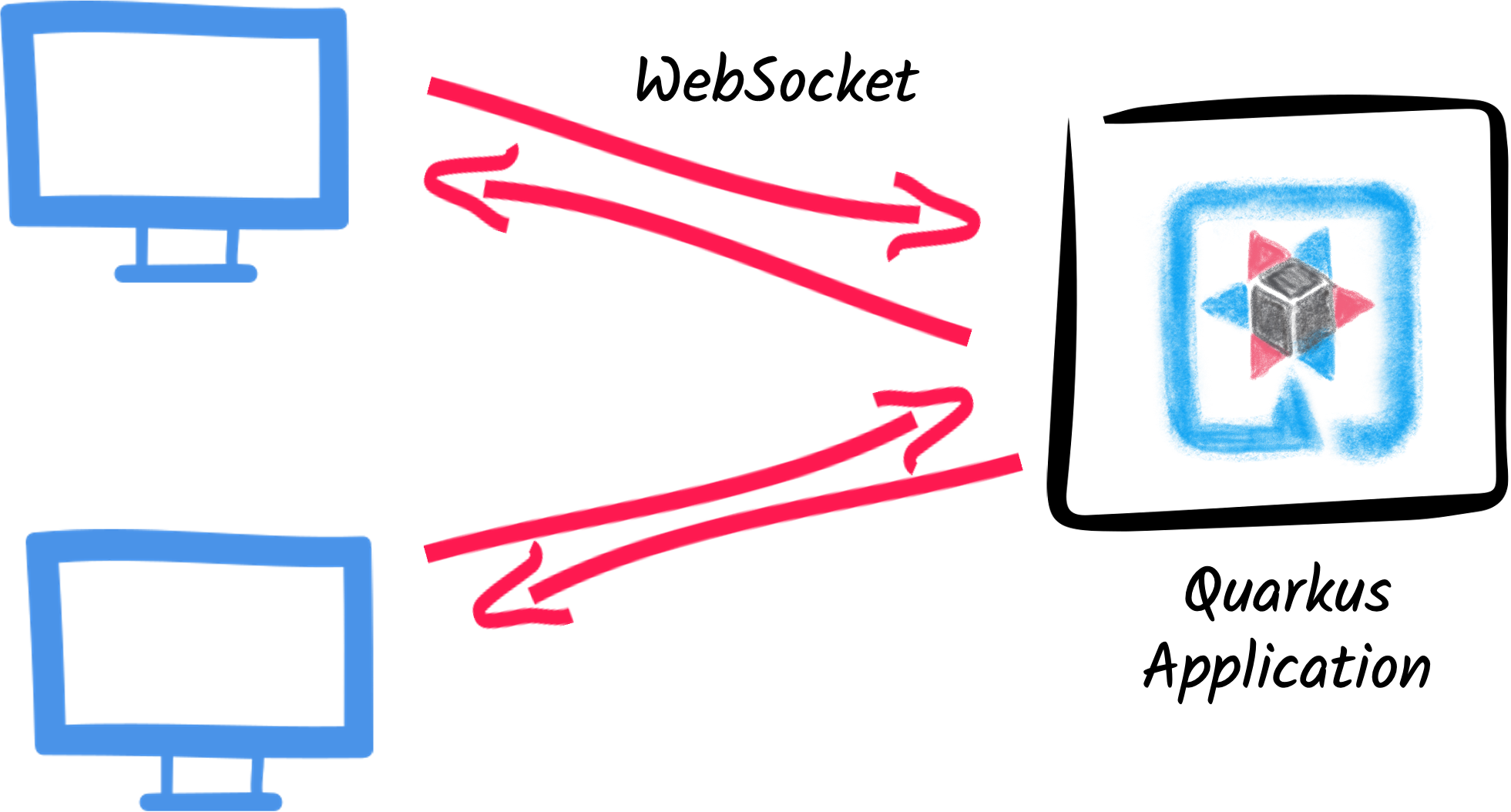
-
Mehrere Endgeräte bzw. Clients können gleichzeitig mit einem Server verbunden sein.
-
Verbindungen sind Bidirektional, d.h. sowohl Server als auch Client können jederzeit Nachrichten senden.
-
Der Server kann von sich aus mit dem Client kommunizieren, ohne dass dieser eine Anfrage stellen muss.
|
Bei SSE (Server-Sent Events) handelt es sich um eine unidirektionale Kommunikation, bei der der Server Daten an den Client sendet, aber der Client nicht direkt auf diese Daten antworten kann. |
13.2. MOA - Message-Oriented Architecture
13.2.1. Vorteile der MOA
Vorteile:
-
Entkopplung:
-
Sender und Empfänger müssen sich nicht kennen.
-
Sie wissen nicht, wie der andere funktioniert oder wo er ist.
-
Wichtig ist nur, dass beide verstehen, wie die Nachricht aufgebaut ist.
-
-
Asynchronität:
-
Der Sender schickt die Nachricht ab und kann sofort weiterarbeiten.
-
Er muss nicht warten, bis der Empfänger fertig ist.
-
-
Fehlertoleranz:
-
Wenn der Empfänger kurz nicht erreichbar ist, werden die Nachrichten zwischengespeichert.
-
Sobald er wieder online ist, bekommt er die Nachrichten.
-
13.2.2. Übungsbeispiel
-
Einen Quarkus Client (Server MQTT) mit dynamischen Topics erstellen.
-
Topics:
(z.B. "home/livingroom/temperature", "home/kitchen/humidity", …) -
Der Client soll Werte abfragen und aktualisieren, wenn neue Werte verfügbar sind.
-
Wie kommunizieren wir mit dem Quarkus Client?
-
Mit einer Qute-Website
-
Auf der Website kann man Antropic eintragen und Werte aktualisieren.
-
Was ist Qute?
-
Quarkus Template mit Qute → PHP für Quarkus
-
Quarkus Qute ist eine schnelle und typsichere Template-Engine.
-
Sie ist gut in Quarkus integriert und funktioniert besonders effizient, auch bei nativen Programmen.
|
YouTuber arconsis Videos zu MQTT |
14. 2026-04-27
14.1. MQTT (Message Queuing Telemetry Transport)
14.1.1. Übersicht
QoS definiert die Zustellungsgarantie einer Nachricht zwischen Sender und Empfänger. Es gibt drei Stufen: 0, 1 und 2.
14.1.2. QoS 0 – „At most once" (Fire & Forget)
Publisher → Broker → Subscriber
(kein ACK) (kein ACK)-
Nachricht wird maximal einmal gesendet
-
Keine Bestätigung, keine Wiederholung
-
Nachricht kann verloren gehen
-
Schnellste und ressourcenschonendste Variante
|
Wann verwenden? Sensordaten, die sich häufig wiederholen (z. B. Temperatur alle 5 Sekunden) – ein verlorenes Paket ist kein Problem. |
14.1.3. QoS 1 – „At least once" (Bestätigt)
Publisher → Broker → Subscriber
← PUBACK ← PUBACK-
Nachricht wird mindestens einmal zugestellt
-
Broker/Client bestätigen den Empfang mit PUBACK
-
Bei ausbleibender Bestätigung → Wiederholung
-
Nachricht kann doppelt ankommen (Duplicate Delivery)
|
Wann verwenden? Wenn keine Nachricht verloren gehen darf, Duplikate aber tolerierbar sind (z. B. Alarmmeldungen). |
14.1.4. QoS 2 – „Exactly once" (Garantiert, einmalig)
Publisher → Broker → Subscriber
← PUBREC
→ PUBREL
← PUBCOMP ← (intern 4-Wege-Handshake)-
Nachricht wird genau einmal zugestellt – garantiert
-
4-Wege-Handshake (PUBLISH → PUBREC → PUBREL → PUBCOMP)
-
Langsamste Variante, höchster Overhead
-
Keine Duplikate, kein Verlust
|
Wann verwenden? Kritische Aktionen wie Zahlungen, Steuerbefehle, medizinische Daten. |
15. 2026-05-11
15.1. Vergleich auf einen Blick
| Eigenschaft | QoS 0 | QoS 1 | QoS 2 |
|---|---|---|---|
Zustellung |
0–1× |
1–n× |
genau 1× |
Geschwindigkeit |
⚡⚡⚡ |
⚡⚡ |
⚡ |
Overhead |
minimal |
mittel |
hoch |
Datenverlust |
möglich |
nein |
nein |
Duplikate |
nein |
möglich |
nein |
Nachrichten gespeichert |
nein |
ja |
ja |
15.2. QoS in Quarkus konfigurieren
15.3. Wichtiger Hinweis: Publisher vs. Subscriber QoS
Das effektive QoS ist immer das Minimum aus Publisher- und Subscriber-QoS:
Publisher QoS 2 + Subscriber QoS 1 = effektiv QoS 1
Publisher QoS 0 + Subscriber QoS 2 = effektiv QoS 0Der Broker kann QoS nur so gut garantieren, wie es beide Seiten unterstützen.
16. 2026-04-20 (A.Mahmutovic)
16.1. MQTT Explorer & Projektarbeit mit Claude Code
16.1.1. MQTT Explorer
-
Verbindung mit der VM von Pointic über den MQTT Explorer hergestellt
-
Ermöglicht das Beobachten und Testen von MQTT-Topics in Echtzeit
16.1.2. Projektstruktur – Ausgangsprojekt
-
Als Ausgangsprojekt dient das Beispielprojekt von Prof. Stütz
-
Das Projekt ist im
labs-Ordner zu finden
16.1.3. story.md – Story-Spezifikation
-
Vorgehen:
story.mderstellen → bei Unklarheiten Fragen stellen lassen → daraus werden fachliche und technische Spezifikationen abgeleitet -
@docs/story.mdkann von Claude Code direkt eingelesen werden -
Im Chat werden die URLs für die Datenabfrage angegeben
16.1.4. Backup-Strategie mit chat.md
-
Den gesamten Chat mit Claude Code in eine neue Datei
chat.mdkopieren -
Zweck: Sicherung des Chats als Backup bei Verlust
-
Frage: Warum löscht man Backups nach 30 Tagen?
-
Speicherplatz: Unbegrenztes Aufbewahren aller Backups würde enormen Speicherplatz verbrauchen
-
Datenschutz (DSGVO): Personenbezogene Daten dürfen nicht länger als nötig gespeichert werden
-
Aktualität: Sehr alte Backups sind meist nicht mehr wiederherstellbar oder relevant
-
17. 2026-04-27 [A. Mahmutovic]
17.1. Softwaretesten – User Stories, Akzeptanzkriterien & Testmethoden
17.1.1. User Stories
-
Eine User Story beschreibt eine Anforderung aus Sicht des Benutzers
-
Format: „Als [Rolle] möchte ich [Funktion], damit [Business Benefit]."
-
Der Business Benefit ist entscheidend – er begründet, warum die Funktion überhaupt umgesetzt wird
-
Beispiel: „Als Kunde möchte ich meine Bestellung verfolgen, damit ich weiß, wann sie ankommt."
17.1.2. Akzeptanzkriterien
-
Definieren, wann eine User Story als fertig gilt
-
Warum sind sie wichtig?
-
Man kann feststellen, ob eine Funktion vollständig umgesetzt wurde
-
Sie sind messbar und überprüfbar
-
Sie erleichtern Entwicklern die Arbeit, da die Erwartungen klar formuliert sind
-
Sie ermöglichen grobe Funktionstests bereits vor der Implementierung
-
17.1.3. Testmethoden nach den Akzeptanzkriterien
Grenzwertanalyse (Boundary Value Analysis)
-
Testet die Grenzen von Eingabebereichen
-
Fehler treten häufig an den Rändern eines Wertebereichs auf
-
Beispiel: Wenn ein Feld Zahlen von 1–100 akzeptiert, werden die Werte 0, 1, 100 und 101 getestet
Äquivalenzklassenanalyse (Equivalence Class Partitioning)
-
Teilt Eingabedaten in Klassen auf, die sich gleichartig verhalten
-
Es reicht, einen Repräsentanten pro Klasse zu testen
-
Beispiel: Eintrittskarten
Klasse Beschreibung Beispielwert Gültig
Alter zwischen 6 und 17 Jahren
12
Ungültig (zu jung)
Alter unter 6 Jahren
3
Ungültig (zu alt)
Alter über 17 Jahren
25
17.2. Lab 08 - Aufgabenstellung Präzisierung
17.2.1. Ergebnis
-
Erstellung einer beliebigen einfachen Appm mit
-
einem REST-Endpoint, der Daten zurückgibt
-
einem GraphQL-Endpoint, der Daten zurückgibt
-
einem WebSocket-Endpoint, der Daten zurückgibt
-
einem MQTT-Client, der Daten zurückgibt (oder empfängt)
-
-
Deployment auf Minikube
-
Deployment auf die LeoCloud
-
Dok generieren lassen (mit Begründung in welcher Form die Dok erstellt wird)